Abstract
Lyrics translation requires both accurate semantic transfer and preservation of musical rhythm, syllabic structure, and poetic style. In animated musicals, the challenge intensifies due to alignment with visual and auditory cues. We introduce Multilingual Audio-Video Lyrics Benchmark for Animated Song Translation (MAVL), the first multilingual, multimodal benchmark for singable lyrics translation. By integrating text, audio, and video, MAVL enables richer and more expressive translations than text-only approaches. Building on this, we propose Syllable-Constrained Audio-Video LLM with Chain-of-Thought (SylAVL-CoT), which leverages audio-video cues and enforces syllabic constraints to produce natural-sounding lyrics. Experimental results demonstrate that SylAVL-CoT significantly outperforms text-based models in singability and contextual accuracy, emphasizing the value of multimodal, multilingual approaches for lyrics translation.
Dataset Overview
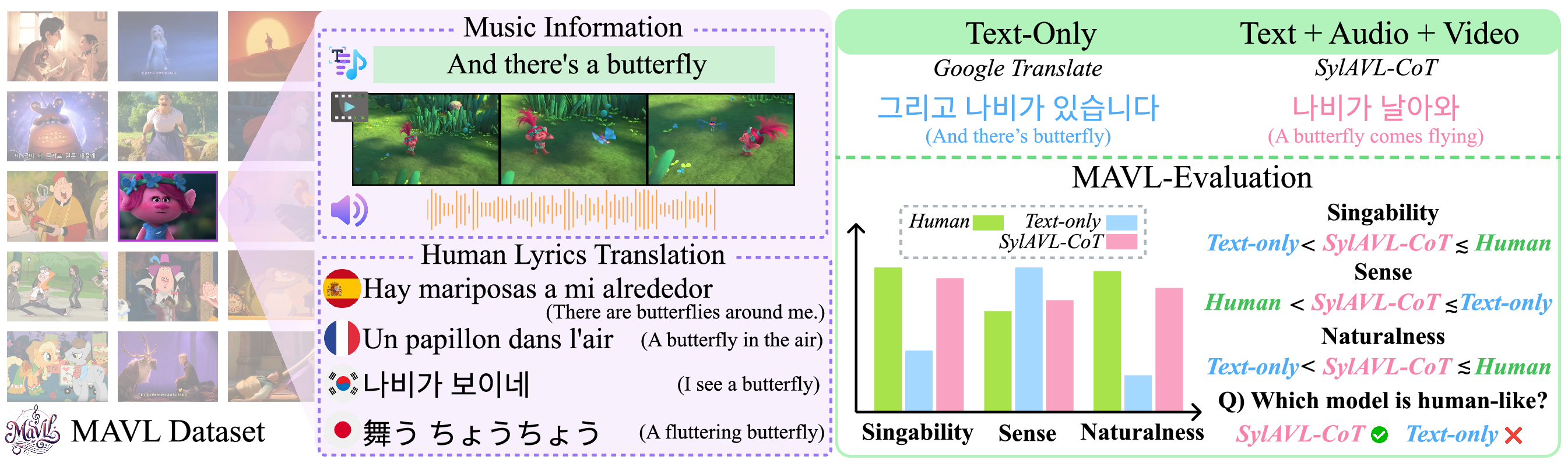
Figure 1: Overview of MAVL Benchmark. This lyric example is part of the OST “Get Back up Again” from “Troll”, produced by Disney Corporation. the left illustrates MAVL Dataset components (music, multilingual human lyrics). The right compares translation outputs, showing our audio-visual SylAVL-CoT produces more vivid and human-like results than text-only models.
MAVL addresses the critical challenge of singable lyrics translation by incorporating multimodal information. Our benchmark includes 228 English songs from animated musicals and their singable translations in Spanish, French, Korean, Japanese.
| Language | # Songs | # Videos | # Sections | # Lines |
|---|---|---|---|---|
| English | 228 | 228 | 1,923 | 6,623 |
| Spanish | 201 | 181 | 1,595 | 5,739 |
| French | 158 | 143 | 1,421 | 4,821 |
| Japanese | 138 | 114 | 1,264 | 4,280 |
| Korean | 133 | 117 | 1,138 | 3,974 |
"# Sections" refers to sections of the lyrics, while "# Lines" denotes the individual lines within those sections.
This multimodal approach enables models to understand not just the textual content, but also the musical rhythm, vocal expressions, and visual context that are crucial for creating singable translations.
Dataset Collection Pipeline

Figure 2: MAVL dataset collection pipeline. (b) visualizes the lyric alignment process, where each color corresponds to English and Korean, respectively. This example lyrics and images are from animated musical content. For more details, refer to the Dataset Structure section.
The MAVL dataset contains lyrics and corresponding audio-video data for 228 songs across five languages (English, Spanish, French, Japanese, and Korean), making it the first dataset to support multilingual lyric translation across three modalities. We collected metadata and original English lyrics from platforms like last.fm and genius, then gathered official dubbed versions in four target languages from lyricstranslate. Human annotators rigorously verified each non-English lyric against its official audio-visual release to ensure authenticity as singable dubbed versions, excluding any unverified or non-matching content. We utilized stable-ts, a Whisper-based tool, to generate precise timestamps for aligning audio, video, and lyrics at the line level. This comprehensive pipeline ensures that all dataset entries contain verified, officially dubbed lyrics synchronized with their corresponding audio and video segments.
Dataset Structure

Figure 3: Detailed structure of the MAVL dataset
To comply with copyright regulations, we provide URLs rather than distributing full lyrics, and reconstruct each line using a compact representation. For English lyrics, we split lines by spaces and record the first letter of each word along with the first and last words (e.g., "Remember me though I have to say goodbye" → ["RmtIhtsg", "Remember", "goodbye"]). For Japanese lyrics, where spacing doesn't naturally separate words, we use morphological analysis tools like MeCab to tokenize the text, then create similar compact representations to enable accurate restoration when the corresponding URL is accessed.
Method: SylAVL-CoT
Syllable-Constrained Audio-Video LLM with Chain-of-Thought
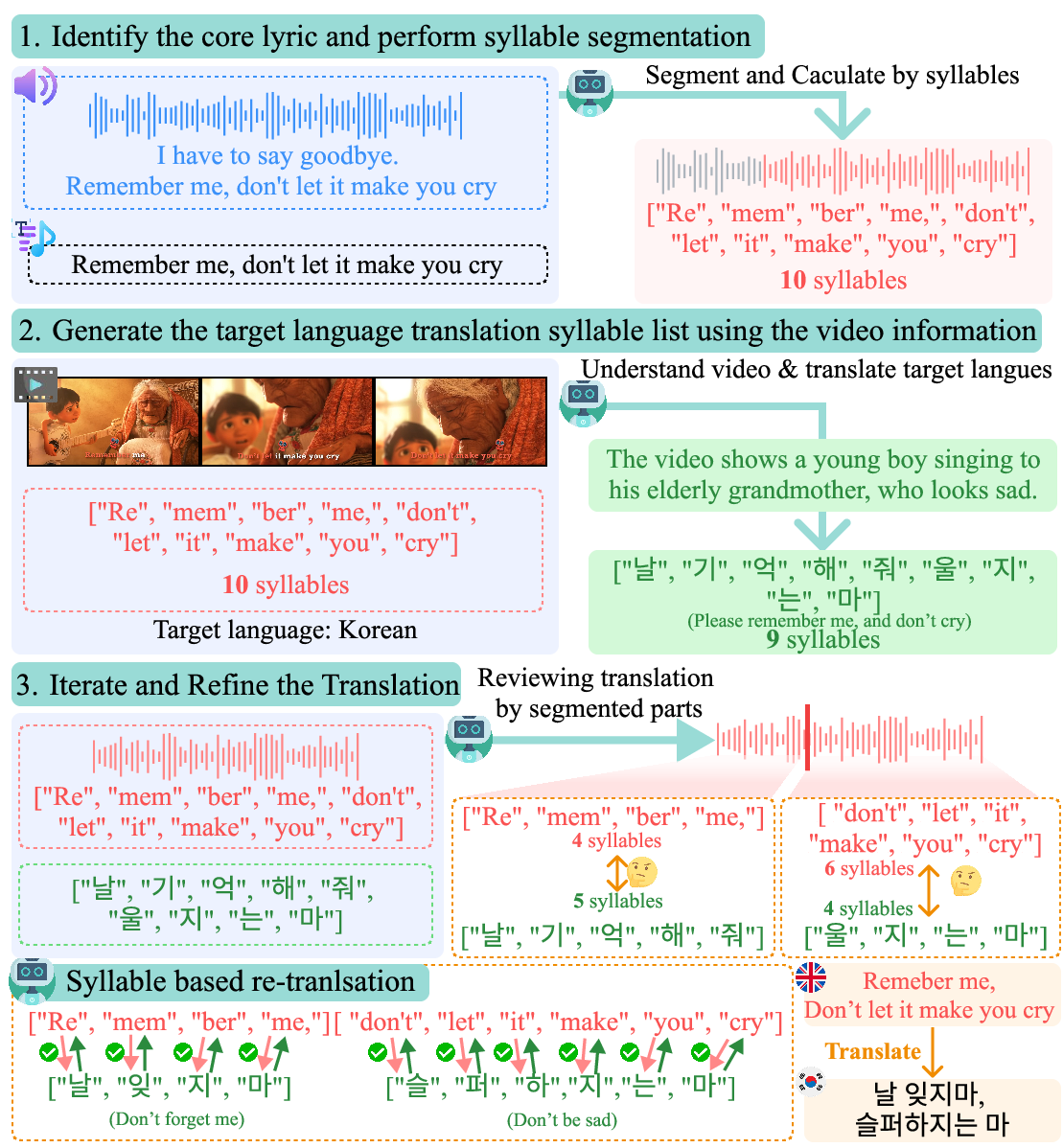
Figure 4: SylAVL-CoT pipeline for lyrics translation.This three-step process segments syllables utilizing audio, translates using video context, and iteratively refines the output to match original syllable counts.
We leverage Gemini 2.0 Flash with Chain-of-Thought (CoT) reasoning to integrate multimodal cues and enforce syllable constraints. Our SylAVL-CoT follows a three-step process to ensure singable translations:
- Identify Core Lyric and Perform Syllable Segmentation: The model locates the relevant audio segment for each lyric line and segments it into syllables based on audible breaks, creating a structural template that maintains the original rhythm and singability.
- Generate Target Translation Using Video Context: Visual cues from the video (thematic elements, animation style, cultural context) guide the translation to capture not only literal meaning but also imagery and artistic nuances, while preserving the original syllable count for musical flow.
- Iterate and Refine the Translation: The model iteratively adjusts the translation through paraphrasing and reordering to achieve the target syllable count while maintaining cultural appropriateness and linguistic coherence, especially challenging when translating between languages with different structures.
Results
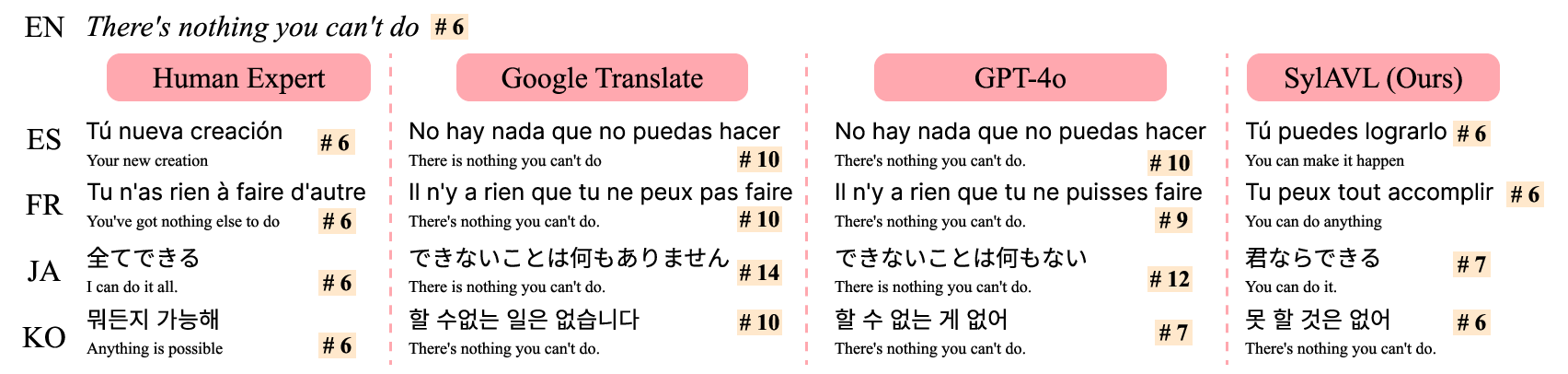
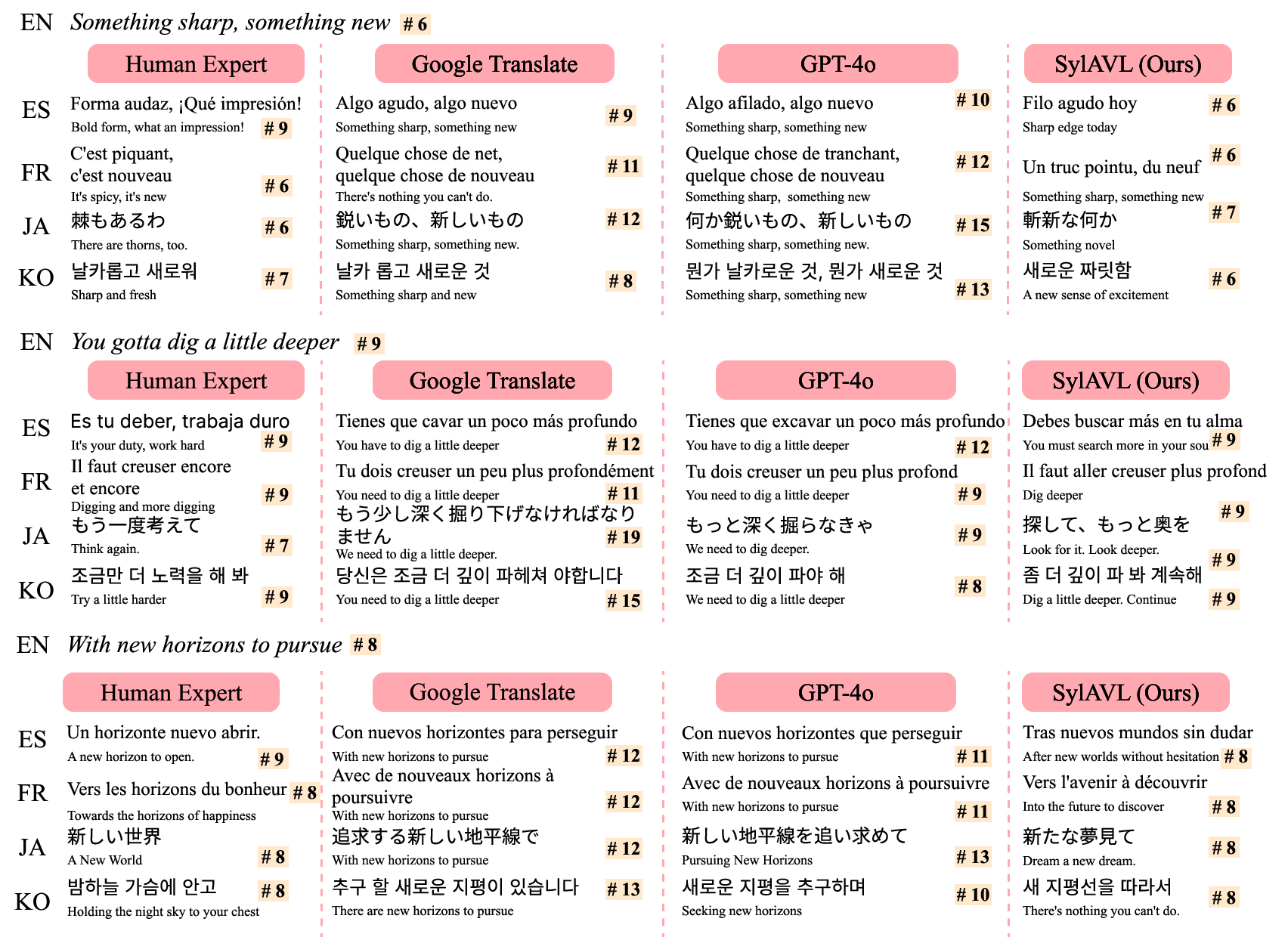
Figure 5: Qualitative examples of SylAVL-CoT compared with baseline methods
We present various qualitative results, as shown in Figure 5. SylAVL-CoT successfully preserves both the original meaning and syllable structure, ensuring singability across different language pairs. The examples demonstrate how our method maintains semantic coherence while adhering to rhythmic constraints, producing translations that are natural and culturally appropriate for the target language.